 |
| A frosty web, courtesy of a spider in my back yard. Image: Yin Liu. |
The year 2014 was the 25th anniversary of the creation of the World Wide Web. There has been, understandably, a great deal of reflection on the significance of this invention, which is generally accepted to have come into existence when Tim Berners-Lee, a software engineer at CERN, the physics research facility in Switzerland, proposed a hypertext solution for information management there. The original proposal is available on the Web, and it’s quite readable: ‘Vague but exciting,’ in the words of Mike Sendall. I’d like my grant adjudicators to say that about my research.
Berners-Lee identified two problems with information management not only at CERN, but at any organisation. The first was that when people left the organisation, information was lost along with them; the organisation needed a way of storing information that was independent of the people in the organisation. The second was that when information was stored, it was encoded into hierarchical, tree-like structures that did not reflect accurately the way in which people actually created, communicated, retrieved, and used information. CERN was (and is) a dynamic, growing organisation; just keeping all the information ‘in a big book’ was not going to work. But the computer-based information management systems that were being used were too rigidly structured. For all sorts of good reasons having to do (I believe) with the way computers work, these systems tended to be modelled as hierarchical trees:
 |
| Python code as a tree. Image: Wikimedia Commons. |
Now here’s a model of literary textual information as a tree. This is from the Text Encoding Initative’s marvellous Gentle Introduction to XML:
‘All the elements of a given document type may be arranged into a hierarchic structure like a family tree, with a single ancestor at one end and many children (mostly the elements containing simple text) at the other. For example, we could represent an anthology containing two poems, the first of which contains two four-line stanzas and the second a single stanza, by a tree structure like the following figure:’

 |
| An airborne squirrel. Image: (cc) Peter Trimming. |
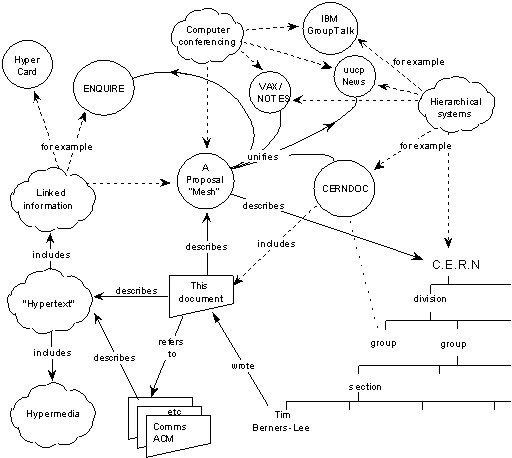 |
| Diagram from Tim Berners-Lee, 'Information Management: A Proposal.' |
A couple of interesting observations from the Berners-Lee proposal:
• ‘In providing a system for manipulating this sort of information, the hope would be to allow a pool of information to develop which could grow and evolve with the organisation and the projects it describes. For this to be possible, the method of storage must not place its own restraints on the information.’
• ‘The system must allow any sort of information to be entered. Another person must be able to find the information, sometimes without knowing what he is looking for.’
medieval textual relations can be a lot more like a network than like a treeNow let’s go back to the first information storage device that Berners-Lee thought of and rejected: ‘a big book’. In the Middle Ages, people did not, of course, have networked computers. They had big books. And what’s interesting about the ways in which medieval people created, organised, and used books is that medieval people did not seem to be as constrained by the physical structures of books as modern people are. Medieval books – especially those that contained texts in vernaculars (non-Latin languages) like English – were dynamic objects: they were always being added to, repurposed, expanded, combined. Different parts of different texts will appear in different manuscripts next to very different sorts of other texts. Anyone who has tried to map out the history of a work like Piers Plowman will realise, surely, that medieval textual relations can be a lot more like a network than like a tree. Was this because medieval people were unsophisticated and disorganised? No, it was because medieval people were human, and their information technology (that is, their books) reflected the way they thought: they connected ideas by linking them in complex ways, not by constraining them in inflexible hierarchies.
I’m certainly not saying that medieval people invented the World Wide Web a thousand years before Tim Berners-Lee did. But what they did with their books is something a lot more World-Wide-Web-like than we usually give them credit for. We’ve often missed seeing this because, for a very long time, we have approached medieval texts through the medium of the print edition, which makes a medieval text more like our idea of a container-like, hierarchically structured book. But when we return to the documents themselves, we are confronted with a messier but perhaps more useful reality.
Yin Liu
References and Further Reading
They’re all in the links above, of course.
No comments :
Post a Comment